Can We Explain Abudance of Equity Factors Just by Data Mining? Surely Not.
Academic research has documented several hundreds of factors that explain expected stock returns. Now, question is: Are all this factors product of data mining? Recent paper by Andrew Chen runs a numerical simulation that shows that it is implausible, that abudance of equity factors can be explained solely by p-hacking …
Author: Chen
Title: The Limits of P-Hacking: A Thought Experiment
Link: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3358905
Abstract:
Suppose that asset pricing factors are just p-hacked noise. How much p-hacking is required to produce the 300 factors documented by academics? I show that, if 10,000 academics generate 1 factor every minute, it takes 15 million years of p-hacking. This absurd conclusion comes from applying the p-hacking theory to published data. To fit the fat right tail of published t-stats, the p-hacking theory requires that the probability of publishing t-stats < 6.0 is infinitesimal. Thus it takes a ridiculous amount of p-hacking to publish a single t-stat. These results show that p-hacking alone cannot explain the factor zoo.
Notable quotations from the academic research paper:
“Academics have documented more than 300 factors that explain expected stock returns. This enormous set of factors begs for an economic explanation, yet there is little consensus on their origin. A p-hacking (a.k.a. data snooping, data-mining) offers a neat and plausible solution. This cynical explanation begins by noting that the cross-sectional literature uses statistical tests that are only valid under the assumptions of classical single hypothesis testing. These assumptions are clearly violated in practice, as each published factor is drawn from multiple unpublished tests. In this well-known explanation, the factor zoo consists of factors that performed well by pure chance.
In this short paper, I follow the p-hacking explanation to its logical conclusion. To rigorously pursue the p-hacking theory, I write down a statistical model in which factors have no explanatory power, but published t-stats are large because the probability of publishing a t-stat ti follows an increasing function p(ti). I estimate p(ti ) by fitting the model to the distribution of published t-stats inHarvey, Liu, and Zhu (2016) and Chen and Zimmermann (2018). The p-hacking story is powerful: The model fits either dataset very well.
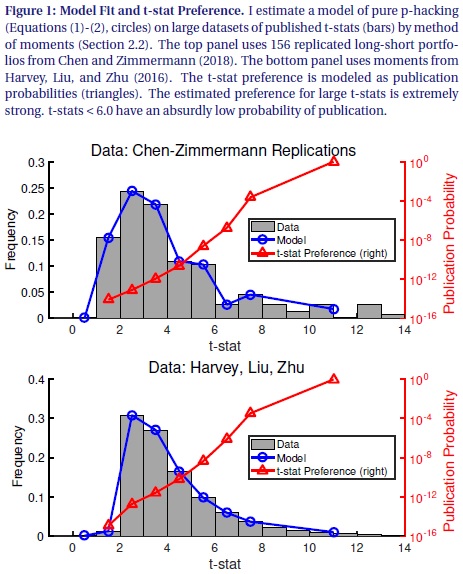
Though p-hacking fits the data, following its logic further leads to absurd conclusions. In particular, the pure p-hacking model predicts that the ratio of unpublished factors to published factors is ridiculously large, at about 100 trillion to 1. To put this number in perspective, suppose that 10,000 economists mine the data for 8 hours per day, 365 days per year. And suppose that each economist finds 1 predictor every minute. Even with this intense p-hacking, it would take 15 million years to find the 316 factors in theHarvey, Liu, and Zhu (2016) dataset.
This thought experiment demonstrates that assigning the entire factor zoo to p-hacking is wrong. Though the p-hacking story appears logical, following its logic rigorously leads to implausible conclusions, disproving the theory by contradiction. Thus, my thought experiment supports the idea that publication bias in the cross-section of stock returns is relatively minor.”
Are you looking for more strategies to read about? Check http://quantpedia.com/Screener
Do you want to see performance of trading systems we described? Check http://quantpedia.com/Chart/Performance
Do you want to know more about us? Check http://quantpedia.com/Home/About
Follow us on:
Facebook: https://www.facebook.com/quantpedia/
Twitter: https://twitter.com/quantpedia
Share onLinkedInTwitterFacebookRefer to a friend

















