BERT Model – Bidirectional Encoder Representations from Transformers
At the end of 2018, researchers at Google AI Language made a significant breakthrough in the Deep Learning community. The new technique for Natural Language Processing (NLP) called BERT (Bidirectional Encoder Representations from Transformers) was open-sourced. An incredible performance of the BERT algorithm is very impressive. BERT is probably going to be around for a long time. Therefore, it is useful to go through the basics of this remarkable part of the Deep Learning algorithm family. [1]
In 2018, the masked-language model – Bidirectional Encoder Representations from Transformers (BERT), was published by Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. The paper is named simply: “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. To date, this publication has more than 60,000 citations. In 2021, was published a literature survey which demonstrated that BERT has become a complex base in Natural language Processing (NPL) experiments. [2]
Transformer (machine learning model)
Transformer-based models have significantly improved the most recent stages in the development of multiple areas of NLP. Nevertheless, understanding what is behind the success and functionality of NPL is still limited. [2] The transformer is defined as “a deep learning model that adopts the mechanism of self-attention, differentially weighting the significance of each part of the input data”. It is largely utilized in the disciplines of computer vision (CV) and natural language processing (NLP). [3]

Figure 1 Natural Language Processing (NLP). [13]
NLP – Natural Language Processing
The automated method of computerized approach text analysis, known as Natural Language Processing (NLP), is based on several theories and technologies. It is a very active area of research and development, thus, there is not a single agreed-upon definition that would satisfy everyone. There are certain aspects, which would be part of the definition. The definition: “Natural Language Processing is a theoretically motivated range of computational techniques for analyzing and representing naturally occurring texts at one or more levels of linguistic analysis for the purpose of achieving human-like language processing for a range of tasks or applications”. [4]
BERT definition
BERT is a framework for machine learning that utilizes transformers. The transformer is where every output element is linked to every input component, and weights are assigned to establish their respective relationships. This is known as attention. BERT leverages the idea of pre-training the model on a larger dataset through unsupervised language modeling. By pre-training on a large dataset, the model can comprehend the context of the input text. Later, by fine-tuning the model on task-specific supervised data, BERT can achieve promising results.
At this stage, two strategies can be applied: fine-tuning and feature-based. ELMo (Embeddings from Language Models, see Related References) uses the feature-based approach, where the model architecture is task-specific. This means that for each task, different models and pre-trained language representations will be used. This means that for each task, different models and pre-trained language representations will be used.
The BERT model employs fine-tuning and bidirectional transformer encoders to comprehend language, earning its name. It is crucial to note that BERT is capable of understanding the complete context of a word. BERT analyzes the words preceding and succeeding a term and determines their correlation.
Unlike other language models like Glove2Vec and Word2Vec, which create context-free word embeddings, BERT provides context by using bidirectional transformers.
B = Bi-directional.
Unlike previous models, which were uni-directional and could only move the context window in one direction, BERT utilizes bi-directional language modeling. This means that BERT can analyze the whole sentence and move in either direction to understand the context.
ER = Encoder representations.
When a text is inputted into a language model, it undergoes encoding before being processed, with the final output also being in an encrypted format requiring decryption. This in-and-out mechanism involves encoding the input and decoding the output, allowing for the language model to effectively process and analyze text data.
T = Transformers
BERT utilizes transformers and masked language modeling for text processing. A key challenge is identifying the context of a word in a particular position, particularly with pronouns. To address this, transformers pay close attention to pronouns and the entire sentence to better understand the context. Masked language modeling also comes into play, where a target word is masked to prevent deviation from meaning. By masking the word, BERT can guess the missing word with fine-tuning.
Model Architecture
The model architecture of the BERT is fundamentally a multi-layer bidirectional Transformer encoder based on the original implementation described in Vaswani et al. (2017). [5]
The transformer architecture consists of an encoder and a decoder in a sequence model. The encoder is used to embed the input, and the decoder is used to decode the embedded output back into a string. This process is similar to encoding-decoding algorithms.
However, the BERT architecture differs from traditional transformers. The model stacks encoders on top of each other, depending on the specific use case. Additionally, the input embeddings are modified and passed to a task-specific classifier for further processing.
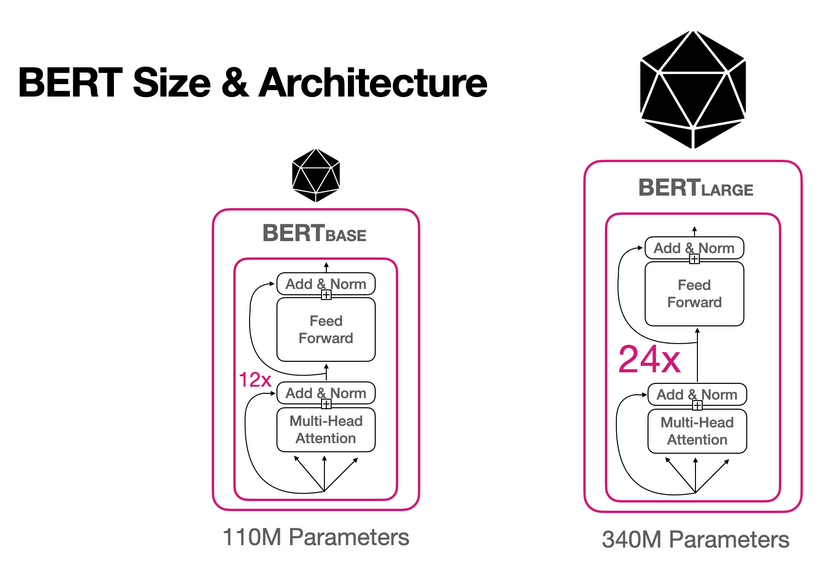
Figure 2 Principle diagram of the BERT model for 110M parameters and 340M parameters. [6]
Tokens in BERT are used to represent words and subwords in the input text. Each token is assigned a fixed dimensional vector representation or embedding. These embeddings are used to capture the contextual relationship between the words in the input text. By using tokens, BERT is able to process text in a way that captures the meaning and context of words and phrases, rather than just their isolated representations. This allows BERT to perform a wide range of natural language processing tasks with high accuracy. [12]
Here are some tokens used in the BERT NLP model architecture:
[CLS] – token represents the start of the sentence and is used to represent the entire input sequence for classification tasks.
[SEP] – token is used to separate two sentences or to separate the question and answer in question-answering tasks.
[MASK] – token is used to mask a word during pre-training. It is also used during fine-tuning to predict the masked word.
[UNK] – token represents an unknown word that is not present in the vocabulary.
[PAD] – token is used for padding to make all the input sequences of the same length.
Here are the components and related words with BERT and their definitions [7]:
Parameters – number of readable variables or values that are available in the model.
Hidden Size – hidden Size is the layers of mathematical functions between input and output. It will assign weight to produce the desired result.
Transformer Layers – Number of transformer blocks. A transformer block will transform a sequence of word representations into a contextualized text or numerical representation.
Processing – the type of processing unit that is used for training the model.
Attention Heads – the transformer block size.
Length of training – time it takes to train the model.
The main parts of BERT and their definitions [12]:
| Part | Definition |
| Tokenizer | BERT’s tokenizer takes raw text as input and breaks it down into individual tokens, which are the basic units of text used in NLP. |
| Input Embeddings | Once the text has been tokenized, BERT’s input embeddings map each token to a high-dimensional vector representation. These vectors capture the meaning of each token based on its context within the sentence. |
| Encoder | BERT uses a multi-layer bidirectional transformer encoder to process the input embeddings. The encoder consists of multiple stacked transformer layers, each of which processes the input embeddings in a different way. |
| Masked LM Head | The Masked Language Model (MLM) head is a task-specific layer that is trained to predict masked tokens in the input sequence. During pre-training, BERT randomly masks some of the input tokens and trains the model to predict their original values based on the context of the surrounding tokens. |
| Next Sentence Prediction Head | The Next Sentence Prediction (NSP) head is another task-specific layer that is trained to predict whether two input sentences are consecutive or not. This helps BERT capture contextual relationships between sentences. |
| Pooler | Finally, BERT’s pooler takes the output of the last transformer layer and produces a fixed-length vector representation of the input sequence. This vector can be used as an input to downstream tasks, such as classification or regression. |
The working mechanism of BERT
The following steps outline how BERT operates.
- Training data in large amounts
BERT is tailored to handle a vast number of words, allowing it to leverage large datasets to gain comprehensive knowledge of English and other languages. However, training BERT on extensive datasets can be time-consuming. The transformer architecture facilitates BERT training, and Tensor Processing Units can speed it up. [7] [12]
- Masked Language Model
The bidirectional learning from text is made possible by the Masked Language Model (MLM) technique. This involves concealing a word in a sentence and prompting BERT to use the words on both sides of the hidden word in a bidirectional manner to predict it. In essence, MLM enables BERT to understand the context of a word by considering its neighboring words. [7] [12]
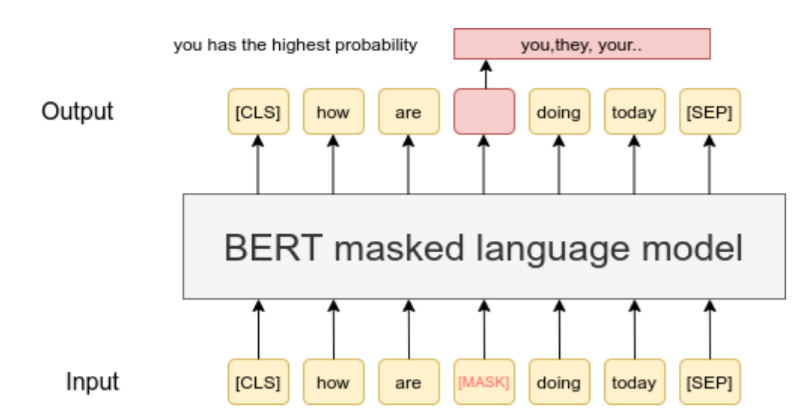
Figure 3 BERT-Original sentence “how are you doing today”. [9]
By considering the word contextually both before and after the hidden text, it can accurately predict the missing word. The bidirectional approach utilized in this process results in the highest level of accuracy. During training, 15% of the tokenized words are randomly masked, and BERT’s objective is to predict the masked words. [12]

Figure 4 Masked Language Model (MLM) technique. [8]
3. Prediction of the Next Sentence
Next Sentence Prediction (NSP) is a technique used by BERT to understand the relationship between sentences. It predicts whether a given sentence follows the previous one, thus learning about the context of the text. During training, BERT is presented with a mix of 50% correct sentence pairs and 50% randomly paired sentences to improve its accuracy. [7] [12]
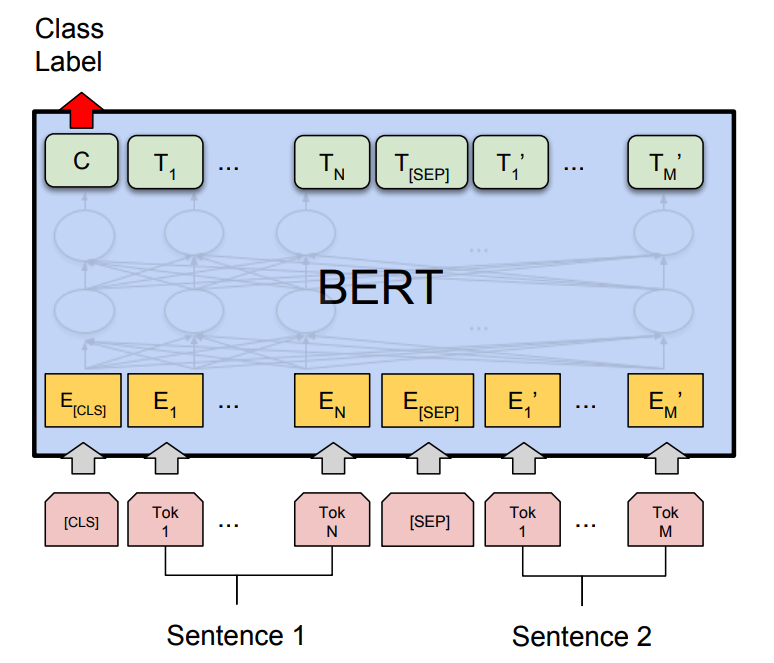
Figure 5 Next Sentence Prediction (NSP) technique [10]
- Transformers
The transformer architecture uses attention, which efficiently parallelizes machine learning training and makes it feasible to train BERT on large data quickly. Attention is a robust deep-learning algorithm first seen in computer vision models. Transformers create differential weights by sending signals to the critical words in a sentence, avoiding the waste of computational resources on irrelevant information.
Transformers leverage encoder and decoder layers to process the input and predict the output, respectively. These layers are stacked on top of each other in a transformer architecture. Transformers are particularly suitable for unsupervised learning tasks as they can process large amounts of data efficiently.

Figure 6 The encoder-decoder structure of the Transformer architecture [14]
Some applications of BERT in NLP
Some of the applications of the BERT Language Model in NLP include:
- Sentiment Analysis
- Language Translation
- Question Answering
- Google Search
- Text Summarization
- Text Matching and Retrieval
- Paragraph Highlighting.
BERT model and its usage in quantitative trading
In this last section of the article, an overview of a few recent studies on the topic of BERT model in the quant analysis is offered. The papers for further reading are always linked below the title.
Overnight Reversal and the Asymmetric Reaction to News
Quantpedia link: https://quantpedia.com/strategies/overnight-reversal-and-the-asymmetric-reaction-to-news/
Link: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4307675
In this study, the authors focused on information contained in financial news and its impact on the U.S. stock market. Previous research showed a quick response to news at the market opening (Boudoukh et al. (2019); Greene and Watts (1996); and others). A modern BERT based natural language model on the Thomson Reuters financial news database was trained and used. This allowed to analyze the market reaction to news sentiment.
There are three main contributions of this study to the literature.
- The authors documented the impact of overnight news sentiment on the market opening price and report a mispricing that leads to a predictable return reversal. The reaction to news sentiment is apparently asymmetric, depending on the direction of the previous day’s return in relation to news sentiment. In the absence of company-specific overnight news, subsequent-day returns can very hardly be predicted.
- Re-investigation of the attention effect reported by Barber and Odean (2008) and Berkman et al. (2012). Those studies state that increased investor attention (indicated by large absolute previous-day returns) leads to elevated prices at market opening followed by a reversal during the trading day. This effect unconditional on news releases was detected, but in the absence of overnight news, it is much less significant than the effect of news sentiment on asset prices.
- The simple trading strategy that exploits overnight reversal by taking a long (short) position in the opening auction of stocks that experienced exceptionally negative (positive) idiosyncratic returns on the previous trading day only if we observe overnight news was presented.
In particular, the authors document a predictable return reversal of previous day returns on days with company-relevant overnight news. When there is no overnight news, predictability is only marginal. This pattern results from investors’ asymmetric responses to news sentiment.
News Sentiment and Equity Returns – BERT ML Model
Quantpedia link: https://quantpedia.com/strategies/news-sentiment-and-equity-returns-bert-ml-model/
Link: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3971880
Main idea of the article is to investigate the impact of financial news on equity returns and introduce a non-parametric model. This model is used to generate a sentiment signal, which is subsequently used as a predictor for short-term, single-stock equity return forecasts. The authors take the BERT model by Google and sequentially train it on financial news from Thomson Reuters (time period from 1996 to 2020). Investigation of the ability of a BERT-based language model to generate a sentiment score from financial news articles for predicting short-term equity returns was done.BERT model was modified for the specific purposes of this study, and it was found that this model is capable of extracting sentimental signal from financial news. This signal has positive correlation with asset returns. It was found that news tend to induce stronger abnormal returns on day t than fresh news, while the information of financial news is incorporated into stock prices within one day. Categorization of news articles into topics can provide information, which can be used as additional features further and this can help make more precise models and improve the model’s ability to predict future asset returns. If only data from the topic “Analyst Forecast” are considered, the most precise forecasts of future asset returns are produced. The authors of this paper concentrate on S&P 500 companies with large market capitalizations.It was discovered that financial news is quickly incorporated into asset prices. Despite of smaller size of the model created by authors, in comparison with FinBERT (Araci, 2019) and full-sized BERT model, it shows superior out-of-sample performance (Table 9). The authors believe that the high quality of the model is conditioned by combination of domain specific pre-training and their deep neural network classifier trained with symmetric cross entropy loss on large annotated financial news dataset.
References:
[2] Rogers, A., Kovaleva, O. and Rumshisky, A. (2021). A Primer in BERTology: What We Know About How BERT Works. Transactions of the Association for Computational Linguistics 8, 842-866.
[3] https://towardsdatascience.com/transformer-in-cv-bbdb58bf335e
[4] Liddy, E. D. (2001). Natural language processing.
[5] Devlin, J., Chang, M. W. and Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805
[6] https://huggingface.co/blog/bert-101
[7] https://www.turing.com/kb/how-bert-nlp-optimization-model-works – what-is-bert?
[8] https://www.geeksforgeeks.org/understanding-bert-nlp/
[9] Jain, A., Ruohe, A., Grönroos, S. A., and Kurimo, M. (2020). Finnish Language Modeling with Deep Transformer Models. arXiv preprint arXiv:2003.11562.
[11] https://devopedia.org/bert-language-model
[12] http://jalammar.github.io/illustrated-bert/
[13] https://d35fo82fjcw0y8.cloudfront.net/2019/05/27153113/what-is-natural-language-processing.jpg
[14] https://machinelearningmastery.com/wp-content/uploads/2021/08/attention_research_1.png
Related References:
ELMo
https://allenai.org/allennlp/software/elmo
BERT model basics
https://en.wikipedia.org/wiki/BERT_(language_model)
https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270
https://huggingface.co/blog/bert-101
Author:
Lukas Zelieska, Quant Analyst
Are you looking for more strategies to read about? Sign up for our newsletter or visit our Blog or Screener.
Do you want to learn more about Quantpedia Premium service? Check how Quantpedia works, our mission and Premium pricing offer.
Do you want to learn more about Quantpedia Pro service? Check its description, watch videos, review reporting capabilities and visit our pricing offer.
Are you looking for historical data or backtesting platforms? Check our list of Algo Trading Discounts.
Would you like free access to our services? Then, open an account with Lightspeed and enjoy one year of Quantpedia Premium at no cost.
Or follow us on:
Facebook Group, Facebook Page, Twitter, Linkedin, Medium or Youtube
Share onLinkedInTwitterFacebookRefer to a friend












