The Impact of Methodological Choices on Machine Learning Portfolios
Studies using machine learning techniques for return forecasting have shown considerable promise. However, as in empirical asset pricing, researchers face numerous decisions around sampling methods and model estimation. This raises an important question: how do these methodological choices impact the performance of ML-driven trading strategies? Recent research by Vaibhav, Vedprakash, and Varun demonstrates that even small decisions can significantly affect overall performance. It appears that in machine learning, the old adage also holds true: the devil is in the details.
This straightforward paper is an excellent reminder that methodological decisions in machine learning (ML) strategies (such as using EW or VW weighting, including micro caps, etc.) significantly impact the results. It’s crucial to consider these decisions like traditional cross-sectional factor strategies, and practitioners such as portfolio managers should always keep this in mind before deploying such a strategy.
The novel integrations of AI (artificial intelligence) and deep learning (DL) techniques into asset-pricing models have sparked renewed interest from academia and the financial industry. Harnessing the immense computational power of GPUs, these advanced models can analyze vast amounts of financial data with unprecedented speed and accuracy. This has enabled more precise return forecasting and has allowed researchers to tackle methodological uncertainties that were previously difficult to address.
Results from more than 1152 choice combinations show a sizeable variation in the average returns of ML strategies. Using value-weighted portfolios with size filters can curb a good portion of this variation but cannot eliminate it. So, what is the solution to non-standard errors? Studies in empirical asset pricing have proposed various solutions. While Soebhag et al. (2023) suggest that researchers can show outcomes across major specification choices, Walter et al. (2023) argue in favor of reporting the entire distribution across all specifications.
While the authors of this paper agree with reporting results across variations, it is wise to advise against a one-size-fits-all solution for this issue. Despite an extensive computation burden, It is possible to compute and report the entire distribution of returns for characteristic-sorted portfolios, as in Walter et al. (2023). However, when machine learning methods are used, documenting distribution as a whole will likely impose an extreme computational burden on the researcher. Although an entire distribution is more informative than a partial one, the costs and benefits of both choices need to be evaluated before giving generalized recommendations.
What are additional ways to control for methodological variation while imposing a modest burden on the researcher? Common recommendations favor first identifying high-impact choices (e.g., weighting and size filters) on a smaller-scale analysis. Researchers can then, at the very least, report variations of results across such high-priority specifications while keeping the rest optional.
Authors: Vaibhav Lalwani, Vedprakash Meshram, and Varun Jindal
Title: The impact of Methodological choices on Machine Learning Portfolios
Link: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4837337
Abstract:
We explore the impact of research design choices on the profitability of Machine learning investment strategies. Results from 1152 strategies show that considerable variation is induced by methodological choices on strategy returns. The non-standard errors of machine-learning strategies are often higher than the standard errors and remain sizeable even after controlling for some high-impact decisions. While eliminating micro-caps and using value-weighted portfolios reduces non-standard errors, their size is still quantitatively comparable to the traditional standard errors.
As always, we present several exciting figures and tables:
Notable quotations from the academic research paper:
“[T]here is ample evidence that suggests that researchers can use ML tools to develop better return forecasting models. However, a researcher needs to make certain choices when using machine learning in return forecasting. These choices include, but are not limited to the size of training and validation windows, the outcome variable, data filtering, weighting, and the set of predictor variables. In a sample case with 10 decision variables, each offering two decision paths, the total specification are 210, i.e. 1024. Accommodating more complex choices can lead to thousands of possible paths that the research design could take. While most studies integrate some level of robustness checks, keeping up with the entire universe of possibilities is virtually impossible. Further, with the computationally intensive nature of machine learning tasks, it is extremely challenging to explore the impact of all of these choices even if a researcher wishes to. Therefore, some of these calls are usually left to the better judgment of the researcher. While the sensitivity of findings to even apparently harmless empirical decisions is well-acknowledged in the literature1, we have only very recently begun to acknowledge the size of the problem at hand. Menkveld et al. (2024) coin the term to Non-standard errors to denote the uncertainty in estimates due to different research choices. Studies like Soebhag et al. (2023) and Walter et al. (2023), and Fieberg et al. (2024) show that non-standard errors can be as large, if not larger than traditional standard errors. This phenomenon raises important questions about the reproducibility and reliability of financial research. It underscores the need for a possibly more systematic approach to the choice of methodological specifications and the importance of transparency in reporting research methodologies and results. As even seemingly innocuous choices can have a significant impact on the final results, unless we conduct a formal analysis of all (or at least, most) of the design choices together, it will be hard to know which choices matter and which do not through pure intuition.
Even in asset-pricing studies that use single characteristic sorting, there are thousands of possible choices (Walter et al. (2023) use as many as 69,120 potential specifications). Extending the analysis to machine learning-based portfolios, the possible list of choices (and their possible impact) further expands. Machine-learning users have to make many additional choices for modeling the relationship between returns and predictor characteristics. With the number of machine learning models available, (see Gu et al. (2020) for a subset of the possible models), it would not be unfair to say that scholars in the field are spoilt for choices. As argued by Harvey (2017) and Coqueret (2023), such a large number of choices might exacerbate the publication bias in favor of positive results.
Interest in applications of Machine learning in Finance has grown substantially in the last decade or so. Since the seminal work of Gu et al. (2020), many variants of machine learning models have been used to predict asset returns. Our second contribution is to this growing body of literature. That there are many choices while using ML in return forecasting is well understood. But are the differences between specifications large enough to warrant caution? Avramov et al. (2023) shows that removing certain types of stocks considerably reduces the performance of machine learning strategies. We expand this line of thought using a broader set of choices that include various considerations that hitherto researchers might have ignored. By providing a big-picture understanding of how the performance of machine learning strategies varies across decision paths, we conduct a kind of large-scale sensitivity analysis of the efficacy of machine learning in return forecasting. Additionally, by systematically analyzing the effects of various methodological choices, we can understand which factors are most infuential in determining the success of a machine learning-based investment strategy.
To summarise, we find that the choices regarding the inclusion of micro-caps and penny stocks and the weighting of stocks have a significant impact on average returns. Further, an increase in sampling window length yields higher performance, but large windows are not needed for Boosting-based strategies. Based on our results, we argue that financials and utilities should not be excluded from the sample, at least not when using machine learning. Certain methodological choices can reduce the methodological variation around strategy returns, but the non-standard errors remain sizeable.
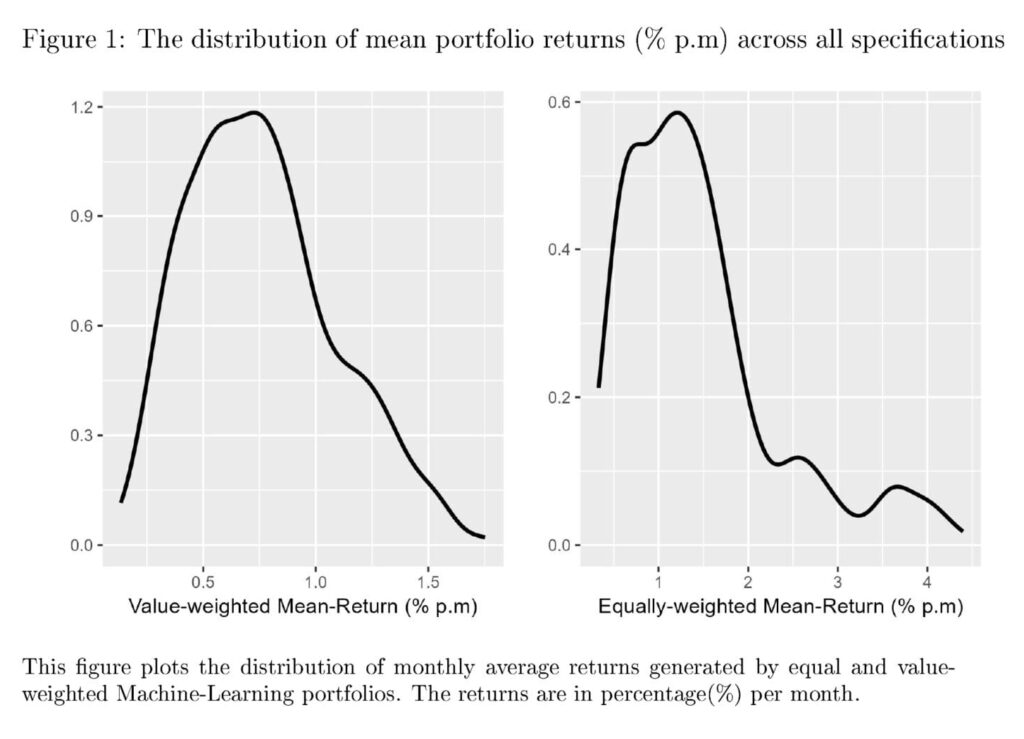
Figure 1 shows the distribution of returns across various specifications. We observe a non-trivial variation in the monthly average returns observed across various choices. The variation appears to be much larger for equally-weighted portfolios compared to value-weighted portfolios, a result we find quite intuitive. The figure also points towards a few large outliers. It would be interesting to further analyze if these extreme values are driven by certain specification choices or are random. The variation in returns could be driven by the choice of the estimator. Studies like Gu et al. (2020) and Azevedo et al. (2023) report significant differences between returns from using different Machine Learning models. Therefore, we plot the return variation after separating models in Figure 2. Figure 2 makes it apparent that there is a considerable difference between the mean returns generated by different ML models. In our sample, Boosted Trees achieve the best out-of-sample performance, closely followed by Neural Networks. Random Forests appear to deliver much lower performance compared to the other two model types. Also, Figure 2 shows that the overall distribution of performance is similar for raw returns as well as Sharpe Ratios. Therefore, for the rest of our analysis, we consider long-short portfolio returns as the standard metric of portfolio performance.
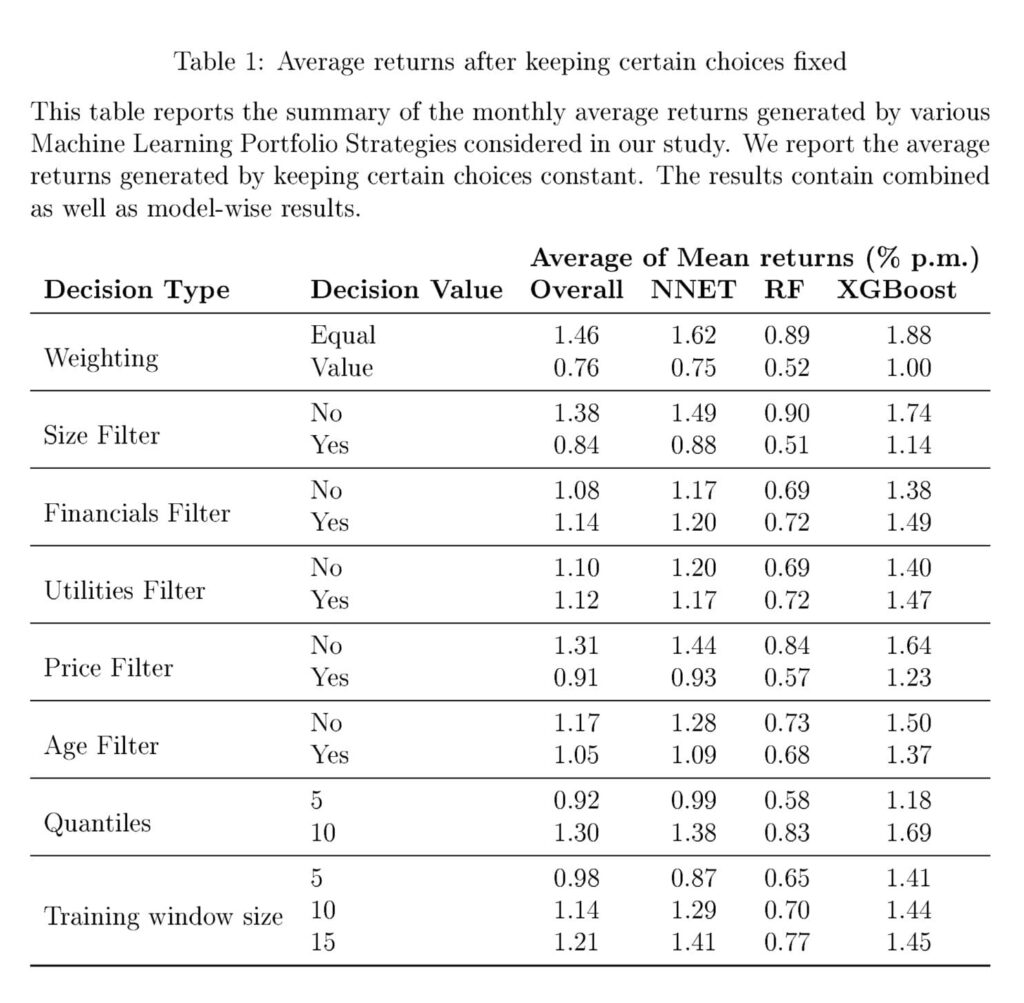
All in all, there is a substantial variation in the returns generated by long-short machine learning portfolios. This variation is independent of the performance variation due to choice of model estimators. We now shift our focus toward understanding the impact of individual decisions on the average returns generated by each of the specifications. Therefore, we estimate the average of the mean returns for all specifications while keeping certain choices fixed. These results are in Table 1.
The results in Table 1 show that some choices impact the average returns more than others. Equal weighting of stocks in the sample increases the average returns. So does the inclusion of smaller stocks. The inclusion of financial and utilities appears to have a slightly positive impact on the overall portfolio Performance. Just like a size filter, the exclusion of low-price stocks tends to reduce overall returns. Further, grouping stocks in ten portfolios yields better performance compared to quintile sorting. On average, larger training windows appear to be better. However, this seems to be true largely for Neural Networks. For Neural Networks, the average return increases from 0.87% to 1.41% per month. For boosting, the gain is from 1.41% to 1.45%. XGBoost works well with just five years of data. It takes at least 15 years of data for Neural Networks to achieve the same performance. Interestingly, while Gu et al. (2020) and (Avramov et al., 2023) both use Neural Networks with a large expanding training window, our results show that similar performance can be achieved with a much smaller data set (but with XGBoost). Finally, the process of keeping only stocks with at least two years of data reduces the returns, but as discussed, this filter makes our results more applicable to real-time investors.”
Are you looking for more strategies to read about? Sign up for our newsletter or visit our Blog or Screener.
Do you want to learn more about Quantpedia Premium service? Check how Quantpedia works, our mission and Premium pricing offer.
Do you want to learn more about Quantpedia Pro service? Check its description, watch videos, review reporting capabilities and visit our pricing offer.
Do you want algorithmic access to the full Quantpedia database via the API? Subscribe to Quantpedia Pro, ask for an API key, and explore the in/out-of-sample statistics, source academic papers, and code snippets — ideal for quantitative research, systematic trading workflows, and AI model training.
Are you looking for historical data or backtesting platforms? Check our list of Algo Trading Discounts.
Or follow us on:
Facebook Group, Facebook Page, Telegram, Twitter, Linkedin, Medium or Youtube
Share onLinkedInTwitterFacebookRefer to a friend










