The Memorization Problem: Can We Trust LLMs’ Forecasts?
Everyone is excited about the potential of large language models (LLMs) to assist with forecasting, research, and countless day-to-day tasks. However, as their use expands into sensitive areas like financial prediction, serious concerns are emerging—particularly around memory leaks. In the recent paper “The Memorization Problem: Can We Trust LLMs’ Economic Forecasts?”, the authors highlight a key issue: when LLMs are tested on historical data within their training window, their high accuracy may not reflect real forecasting ability, but rather memorization of past outcomes. This undermines the reliability of backtests and creates a false sense of predictive power.
Authors: Alejandro Lopez-Lira, Yuehua Tang, Mingyin Zhu
Title: The Memorization Problem: Can We Trust LLMs’ Economic Forecasts?
Link: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5217505
Abstract:
Large language models (LLMs) cannot be trusted for economic forecasts during periods covered by their training data. We provide the first systematic evaluation of LLMs’ memorization of economic and financial data, including major economic indicators, news headlines, stock returns, and conference calls. Our findings show that LLMs can perfectly recall the exact numerical values of key economic variables from before their knowledge cutoff dates. This recall appears to be randomly distributed across different dates and data types. This selective perfect memory creates a fundamental issue—when testing forecasting capabilities before their knowledge cutoff dates, we cannot distinguish whether LLMs are forecasting or simply accessing memorized data. Explicit instructions to respect historical data boundaries fail to prevent LLMs from achieving recall-level accuracy in forecasting tasks. Further, LLMs seem exceptional at reconstructing masked entities from minimal contextual clues, suggesting that masking provides inadequate protection against motivated reasoning. Our findings raise concerns about using LLMs to forecast historical data or backtest trading strategies, as their apparent predictive success may merely reflect memorization rather than genuine economic insight. Any application where future knowledge would change LLMs’ outputs can be affected by memorization. In contrast, consistent with the absence of data contamination, LLMs cannot recall data after their knowledge cutoff date. Finally, to address the memorization issue, we propose converting identifiable text into anonymized economic logic—an approach that shows strong potential for reducing memorization while maintaining the LLM’s forecasting performance.
As such, we present several interesting figures and tables:

Notable quotations from the academic research paper:
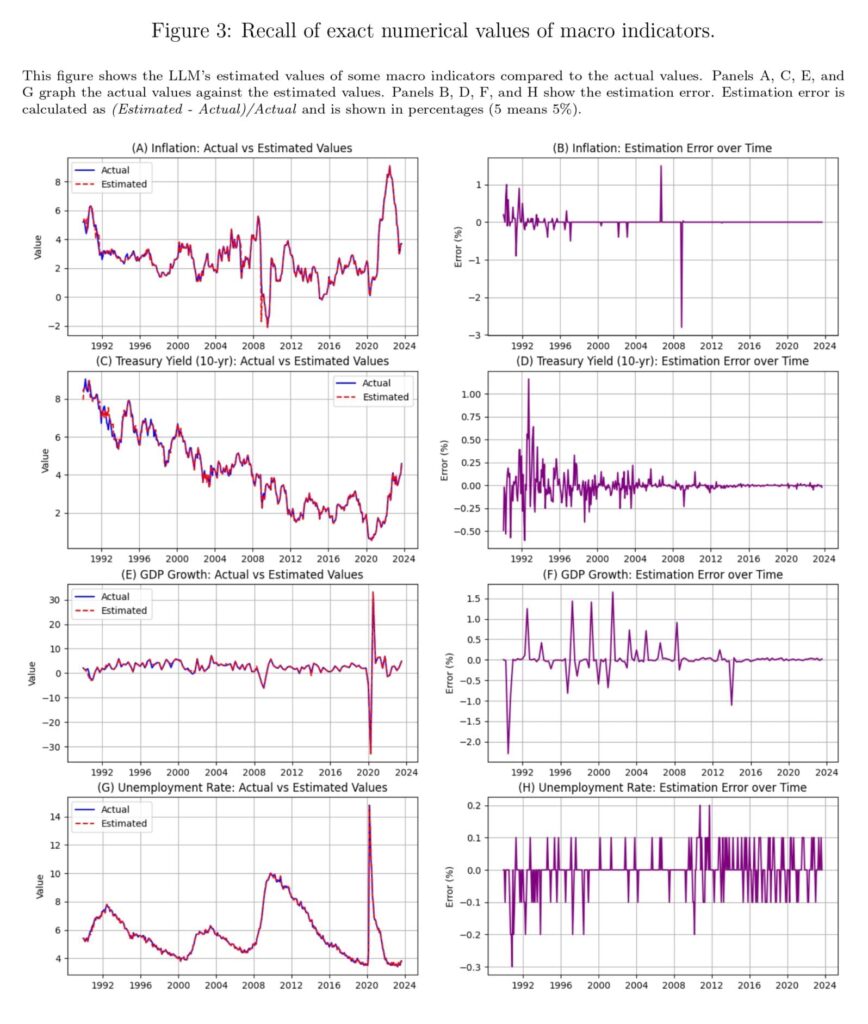
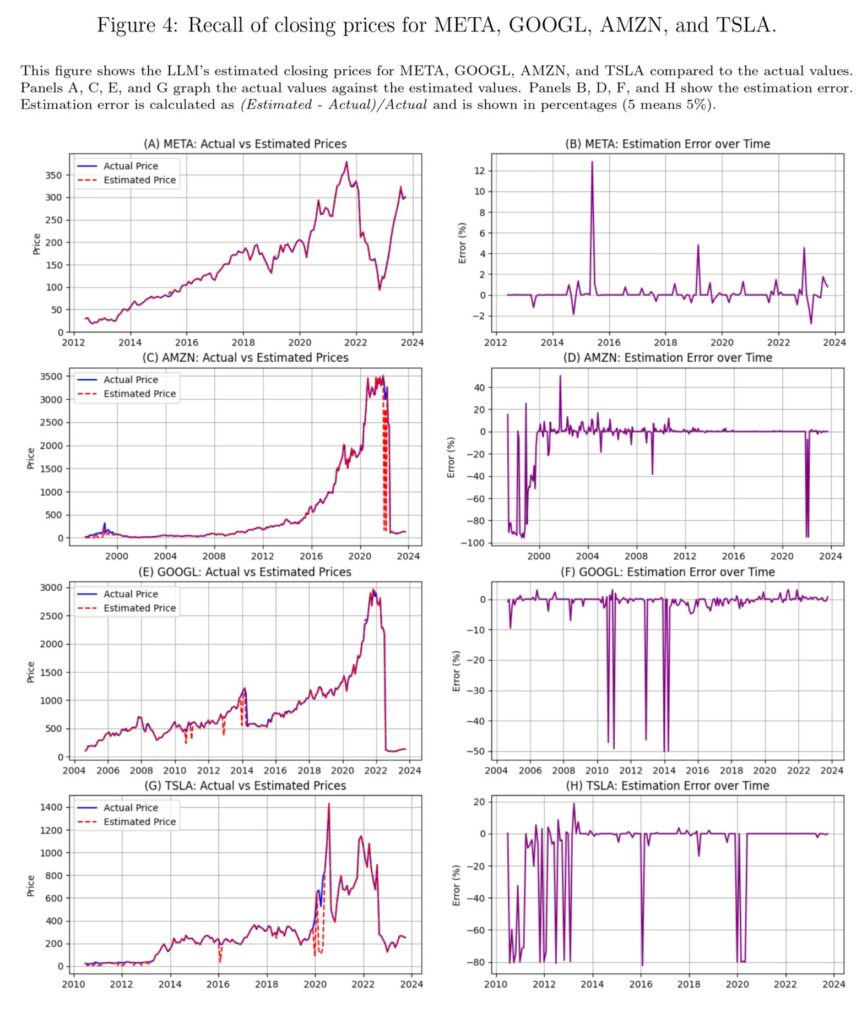
“Using a novel testing framework, we show that LLMs can perfectly recall exact numerical values of economic data from their training. However, this recall varies seemingly randomly across different data types and dates. For example, before its knowledge cutoff date of October 2023, GPT-4o can recall specific S&P 500 index values with perfect precision on certain dates, unemployment rates accurate to a tenth of a percentage point, and precise quarterly GDP figures. Figure 1 shows the LLM’s memorized values of the stock market indices compared to the actual values and the associated errors. LLMs can reconstruct closely the overall ups and downs of the stock market indices, with some substantial occasional errors appearing, seemingly at random.
The problem can manifest when LLMs are asked to analyze historical data they have been exposed to during training and instructed not to use their knowledge. For example, when prompted to forecast GDP growth for Q4 2008 using only data up to Q3 2008, the model can activate two parallel cognitive pathways: one that generates plausible economic analysis about factors like consumer spending and industrial production and another that subtly accesses its memorized knowledge of the actual GDP contraction during the financial crisis. The resulting forecast appears analytically sound yet achieves suspiciously high accuracy because it’s anchored to memorized outcomes rather than derived from the provided information. This mechanism operates beneath the model’s visible outputs, making it virtually impossible to detect through standard evaluation methods. The fundamental problem is analogous to asking an economist in 2025 to “predict” whether subprime mortgage defaults would trigger a global financial crisis in 2008 while instructing them to “forget” what happened. Such instructions are impossible to follow when the outcome is known.
The results reveal an evident ability to recall macroeconomic data. For rates, the model demonstrates near-perfect recall, with Mean Absolute Errors ranging from 0.03% (Unemployment Rate) to 0.15% (GDP Growth) and Directional Accuracy exceeding 96% across all indicators, reaching 98% for 10-year Treasury Yield and 99% for Unemployment Rate. This result suggests that GPT-4o has memorized these percentage-based indicators with high fidelity.
We observed a similar pattern when we extended our test to ask the model to provide both the headline date and the corresponding S&P 500 level on the next trading day. For the pre-training period, the model achieved high temporal accuracy while maintaining nearperfect recall of index values (mean absolute percent error of just 0.01%). For post-training headlines, both date identification and index level predictions became significantly less accurate.
These results connect to our earlier findings on macroeconomic indicators, where high pre-cutoff accuracy reflected memorization. The strong post-cutoff performance without user prompt reinforcement mirrors the suspiciously high accuracy seen in other tests when constraints were not strictly enforced, suggesting that GPT-4o defaults to using its full knowledge unless explicitly and repeatedly directed otherwise. The high refusal rate with dual prompts aligns with weaker recall for less prominent data, as seen in small-cap stocks, indicating partial compliance but not complete isolation from memorized information. This failure to fully respect cutoff instructions reinforces the challenge of using LLMs for historical forecasting, as their outputs may subtly incorporate memorized data, necessitating postcutoff evaluations to ensure genuine predictive ability.”
Are you looking for more strategies to read about? Sign up for our newsletter or visit our Blog or Screener.
Do you want to learn more about Quantpedia Premium service? Check how Quantpedia works, our mission and Premium pricing offer.
Do you want to learn more about Quantpedia Pro service? Check its description, watch videos, review reporting capabilities and visit our pricing offer.
Do you want algorithmic access to the full Quantpedia database via the API? Subscribe to Quantpedia Pro, ask for an API key, and explore the in/out-of-sample statistics, source academic papers, and code snippets — ideal for quantitative research, systematic trading workflows, and AI model training.
Are you looking for historical data or backtesting platforms? Check our list of Algo Trading Discounts.
Or follow us on:
Facebook Group, Facebook Page, Telegram, Twitter, Linkedin, Medium or Youtube
Share onLinkedInTwitterFacebookRefer to a friend










