Impact of Business Cycles on Machine Learning Predictions
As an old investing adage goes, “Everybody’s a genius in a bull market.” It is easy to fall victim to the Dunning-Kruger effect, where attribution bias makes us mistake our luck for abilities. When the business cycles change, there are great problems with precise stock price predictability. And this is not the only problem for humans, who are baffled by many mental heuristics. Machine learning algorithms experience similar problems, too. What is happening, and why is it so? A new paper by Wang, Fu, and Fan gives an explanation and proposes some remedies …
From observations of market volatility and model performance across recession and non-recession periods, existing ML model performances are highly correlated with market volatility, regardless of the details of model structures. Paper Stock Price Predictability and the Business Cycle Via Machine Learning demonstrated that even under optimal hyperparameter fine-tuning, ML models still deliver inferior performance in five out of the seven NBER recession periods compared to their counterparts’ performance in expansion periods.
Including recession data in the training set or incorporating the risk-free rate, technical indicators, and macroeconomic variables as predictors yielded mixed success in improving model performance. More effort is needed to enhance the performance of ML models with volatile data.
The authors propose an early recession identification method that can be easily extended from pre-trained neural network forecasting models to identify recessions while predicting stock prices. Their proposal involves training a decoder that reconstructs the inputs to the forecasting model from its intermediate outputs. The reconstruction error between the input and the reconstructed input is a recession index. A higher reconstruction error suggests a higher likelihood of a recession. The decoder’s reconstructed inputs also serve as price and factor expectations.
Finance ML practitioners are suggested to evaluate their ML models in both recession and non-recession periods to gain insights into the performance dynamics throughout the business cycle. Early indications of recessions could assist decision-makers in managing the impending negative consequences of increased volatility on applications reliant on machine learning forecasting models, which are encouraging, such as the one presented.
Authors: Li Rong Wang, Hsuan Fu, and Xiuyi Fan
Title: Stock Price Predictability and the Business Cycle Via Machine Learning
Link: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4703458
Abstract:
We investigate the impact of business cycles on machine learning (ML) predictions using the S&P 500 index. Our findings reveal that ML models generally under-perform during most recessions, and incorporating recession history, risk-free rate, velocity, momentum, and macroeconomic variables does not necessarily enhance their performance. Upon examining recessions where models exhibit strong performance, we observe that these periods exhibit lower market volatility compared to other recessions. This suggests that the improved performance is primarily influenced by factors such as effective monetary policies that stabilize the market, rather than the inherent merit of ML methods. Nonetheless, providing advance notice of the beginning of a recession could help mitigate the negative impacts on model performance. Therefore, we propose a neural network architecture aimed at detecting the onset of recessions. Additionally, we recommend that ML practitioners evaluate their models across both recessions and expansions to gain comprehensive insights into their performance. Preprint submitted to Decision Support Systems October 29, 2023
As always, we present several interesting figures and tables:
Notable quotations from the academic research paper:
“Despite recent successes in developing ML models for the prediction of financial prices of different assets, there is little discussion in the literature about the impact of business cycles and market volatility on stock price forecasting with ML models. On the contrary, several studies have attempted to predict business cycle phases using ML techniques. These studies approached the task as a conventional classification problem [19, 20, 21]; in this context, generic ML classifiers were trained on historical data labeled with categorical tags representing the presence or absence of market crashes in the near future. However, applying such approaches directly to recession forecasting may not be optimal due to the imbalanced nature of recession forecasting data. A more promising alternative involves treating this issue as an anomaly detection problem.
This paper fills both gaps by exploring the data-shifting effects of recession market volatility on ML models and anomaly detection methods for business cycle phase forecasting[.]
Our main finding mostly confirms the conjecture that predictions tend to be less accurate during recession periods compared to expansion periods. For the majority of models, we report larger forecasting errors in recessions than in expansions. However, we note that a few models do not coincide with our conjecture. We observe that these models were all evaluated on the two recessions in the late 1970s. The oil crisis combined with high inflation in this period resulted in a major change in monetary policy-making. We argue that this explains the low volatility in the stock market during these periods. Thus, these two recessions should be considered exceptions in our analysis.
Second, on adding the recession observations into the in-sample (training) set and we find that half of the models (22 out of 42) show signs of improved forecasting performance. However, there is no clear pattern on whether a specific type of model (e.g., LSTM, GRU, or BLSTM) or some specific periods benefit from such inclusion. Hence, the benefit of including recession data remains somewhat opaque for forecasting in recessions.
Third, we also explored the impact of additional inputs on model performance. Specifically, we introduced the risk-free rate, stock price velocity and momentum, and macroeconomic variables. Among the 42 models tested, 17 models showed improved forecasting accuracy when the risk-free rate was included. Similarly, 24 out of 42 models exhibited enhanced accuracy with the inclusion of velocity and momentum features. These observations suggest that the inclusion of risk-free-rate, velocity and momentum features may have a positive impact on stock price forecasting, although the effect was not consistently observed across all models. Interestingly, the incorporation of macroeconomic variables improved recession prediction performance for models trained solely with expansion data (7 out of 9 models), but not for models trained using both recession and non-recession data (4 out of 9 models).
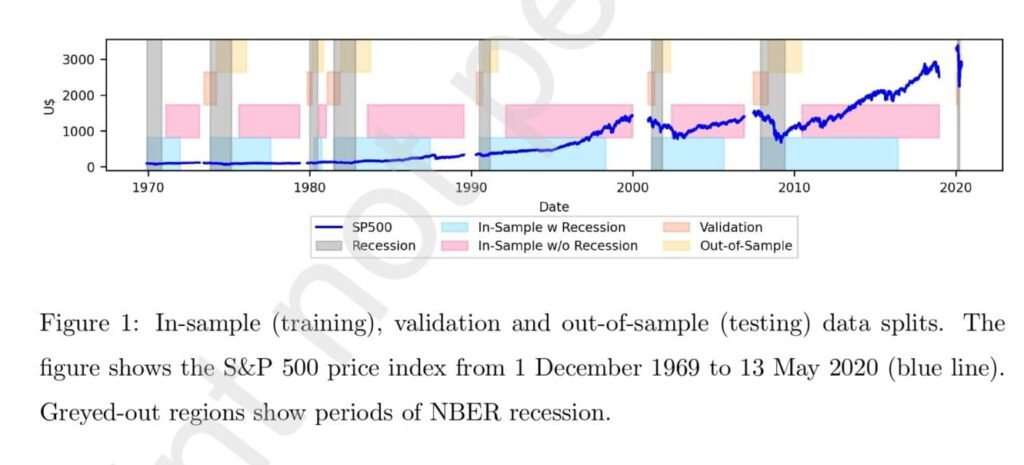
The data were divided into seven overlapping subperiods (aligned with the number of recessions by the National Bureau of Economic Research (NBER)) as illustrated in Figure 1. Each subperiod consists of four consecutive data splits and spans two adjacent recessions to maximize the use of the collected data (resulting in subperiods with varying lengths). Each model was trained on either “In-Sample With Recession (ISWR)” or “In-Sample Without Recession (ISWOR)”, hyper-parameter-tuned with “Validation”, and evaluated on OOS from a single subperiod.
In Figure 1, we observe that during recession periods, stock prices exhibit varying rates of decline. This observation motivates our investigation into whether the inclusion of velocity (price changes) and momentum (velocity changes) indicators calculated from stock prices could enhance predictions during recessions.
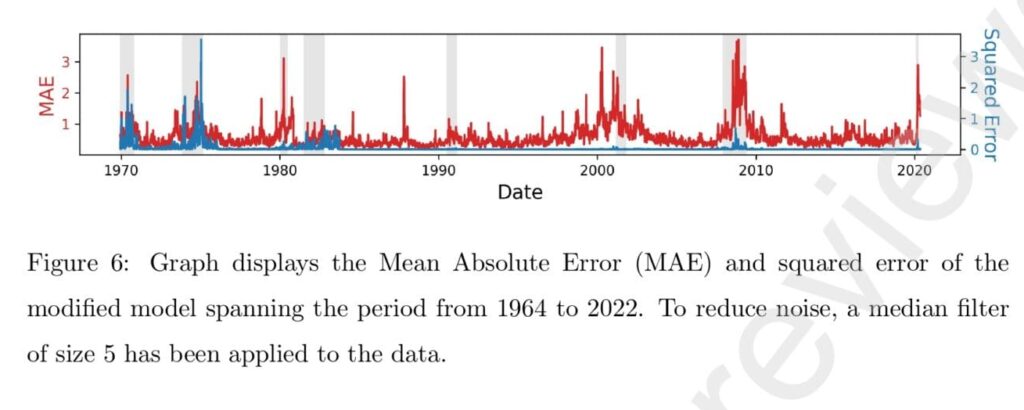
Our method involves attaching a decoder to a trained neural network forecasting model, which reconstructs the input from the outputs of any intermediate layer of the prediction model. The reconstruction MAE (mean absolute error; the magnitude of difference between the reconstructed and original input; chosen for its robustness to outliers [37] when compared to other error metrics like root mean squared error) is hypothesized to serve as a reliable measure of data unfamiliarity. By training the model solely on data from non-recession periods, we anticipate being able to distinguish between recession and expansion periods, thereby providing an accurate estimation of the onset and end of each recession. From a financial perspective, the reconstructed input represents expectations of prices and factors, which serve as benchmark information for investment decisions. The reconstruction MAE quantifies the deviation between the expected and realized values of prices and factors. Figure 6 shows the MAE of such a model across all seven subperiods. It is evident that during recessions, the MAE exhibits a notable increase, while during non-recession periods, the MAE remains relatively low. This observation highlights the potential of our proposed model for early recession identification.”
Are you looking for more strategies to read about? Sign up for our newsletter or visit our Blog or Screener.
Do you want to learn more about Quantpedia Premium service? Check how Quantpedia works, our mission and Premium pricing offer.
Do you want to learn more about Quantpedia Pro service? Check its description, watch videos, review reporting capabilities and visit our pricing offer.
Do you want algorithmic access to the full Quantpedia database via the API? Subscribe to Quantpedia Pro, ask for an API key, and explore the in/out-of-sample statistics, source academic papers, and code snippets — ideal for quantitative research, systematic trading workflows, and AI model training.
Are you looking for historical data or backtesting platforms? Check our list of Algo Trading Discounts.
Or follow us on:
Facebook Group, Facebook Page, Twitter, Linkedin, Medium or Youtube
Share onLinkedInTwitterFacebookRefer to a friend
















