Corporate Bond Factors: Replication Failures and a New Framework
The replication crisis in social sciences (and, of course, finance) is an often covered topic (see also our articles How do Investment Strategies Perform After Publication and In-Sample vs. Out-of-Sample Analysis of Trading Strategies). In vs. out-of-sample tests are usually performed on equity factors as data are available. However, the Copenhagen Business Schools, in close cooperation with AQR Capital Management, went in a different direction and built a database of realistic corporate bond data and took a closer look at the precision of corporate bonds forecasting methodologies. We applaud them for that, as working with the corporate bond data is challenging, and their work sheds a little light on this important part of the financial markets.
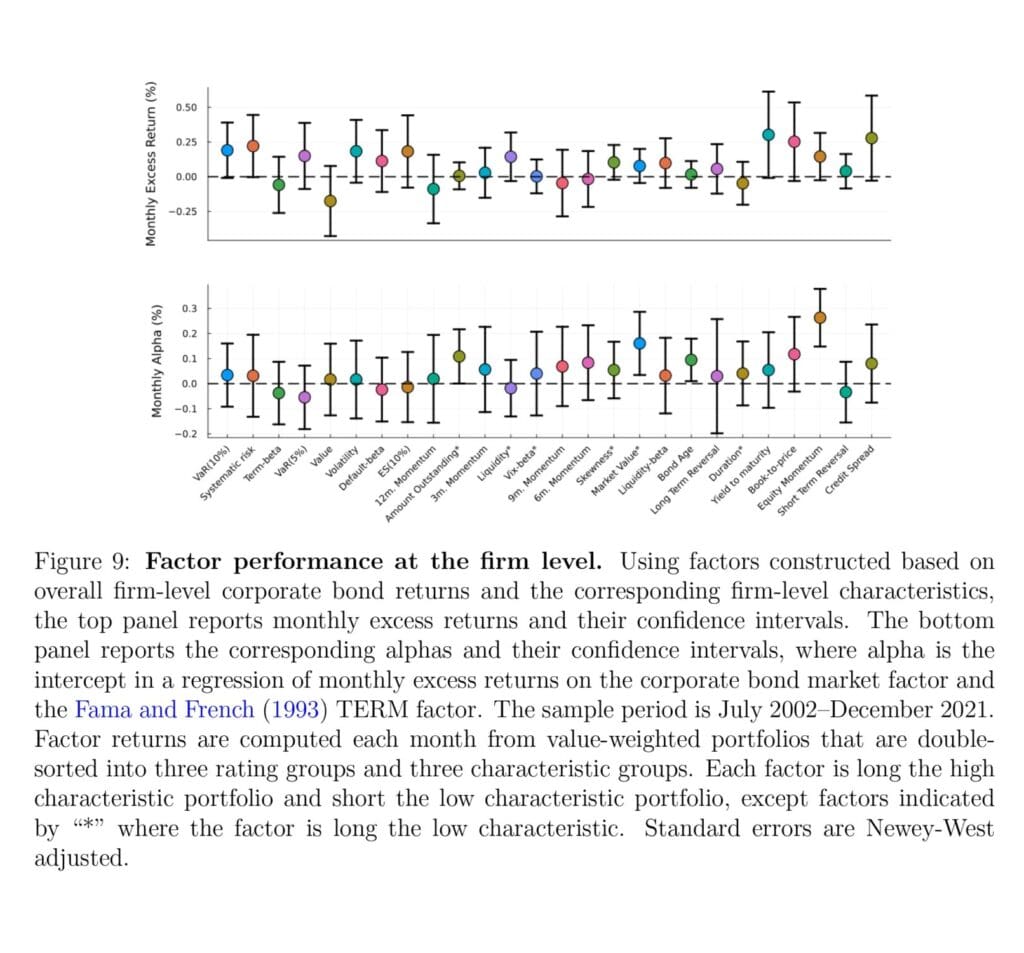
The authors are pro-active and propose a common methodology for factor construction, which can be applied at the level of individual bonds and representative firm-level corporate bond returns. Using this relatively clean data and robust methods, they show that most corporate bond factors from the literature fail to replicate, but a minority of factors remain significant.
On top of that, analyzing corporate bond factors based on equity signals, authors found a number of significant new factors. These findings challenge most of the rapidly growing literature on corporate bond factors and simultaneously challenge the opposite view that the CAPM largely works for corporate bonds (Fama and French (1993), Dickerson et al. (2023)).
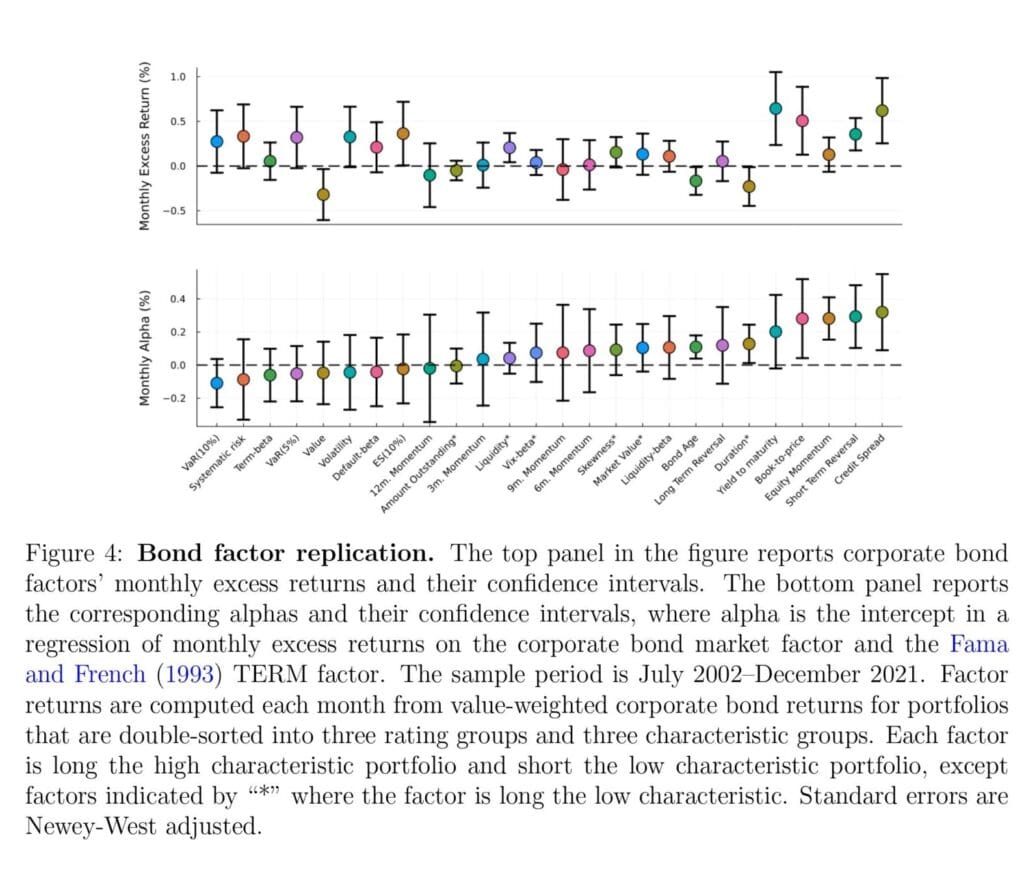
From the list of concluding pictures, we recommend paying attention mainly to Figures 4 and 5, which show corporate bond factors’ monthly returns and their corresponding confidence intervals using the cleaned data.
Authors: Jens Dick-Nielsen, Peter Feldhütter, Lasse Heje Pedersen, Christian Stolborg
Title: Corporate Bond Factors: Replication Failures and a New Framework
Link: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4586652
Abstract:
We demonstrate that the literature on corporate bond factors suffers from replication failures, inconsistent methodological choices, and the lack of a common error-free dataset. Going beyond identifying this replication crisis, we create a clean database of corporate bond returns where outliers are analyzed individually and propose a robust factor construction. Using this framework, we show that most, but not all, factors fail to replicate. Further, while traditional factors are constructed from individual bonds, we create representative firm-level bonds, showing which bond signals work at the firm-level. Lastly, we show that a number of equity signals work for corporate bonds. In summary, most factors fail, but so does the CAPM for corporate bonds.
And, as you are used to know, we present several interesting figures and tables:
Notable quotations from the academic research paper:
“In short, we find that most of the corporate bond factors in the literature fail to replicate, in large part due to problems with the underlying data, combined with varying and non-robust ways of dealing with these data errors. We present a new framework of clean data and robust factor construction, finding a minority of significant corporate bond factors. We also present a way to aggregate each firm’s many bonds into a single time series of representative bond returns for each firm. Using these firm-level corporate bond returns as test assets, we study factor returns based on the existing corporate-bond signals as well as signals from the literature on equity factors. We intend to make our clean corporate bond returns, firm-level returns, factor returns, and code available to researchers.
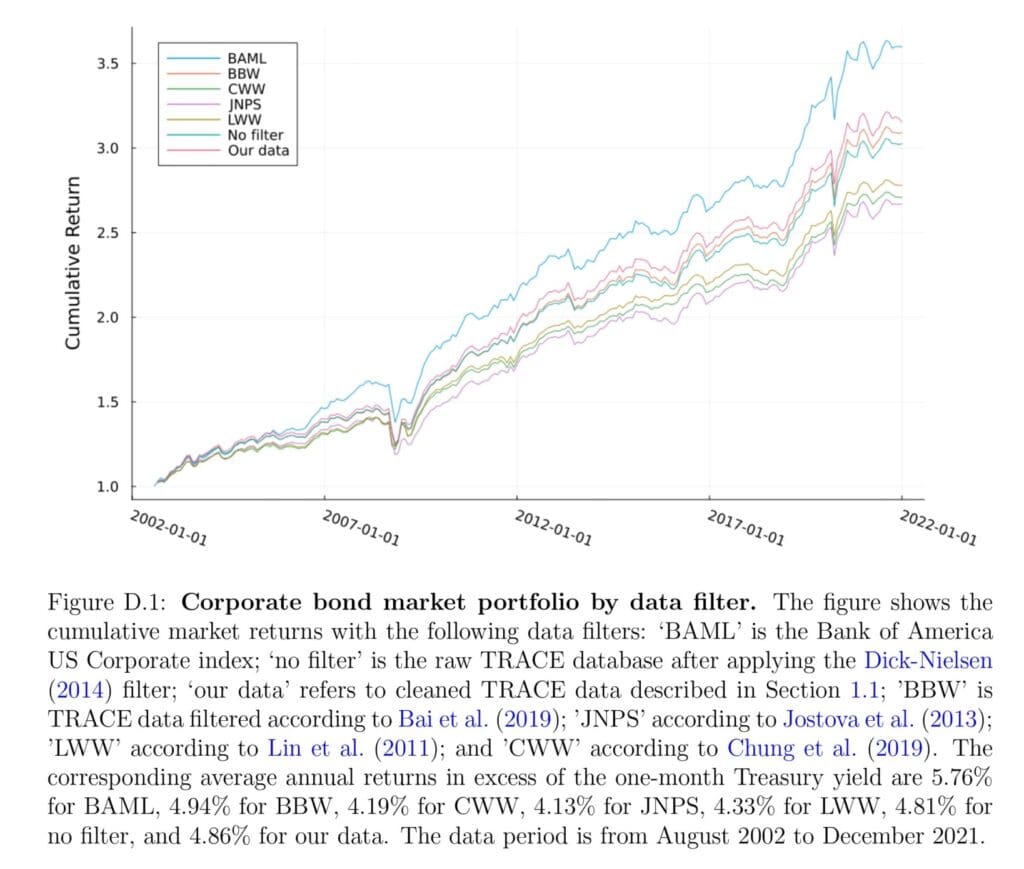
Reproduction: Data-cleaning method matters. Our first finding is that basic data-cleaning choices lead to significant replication problems in the corporate bond literature. To analyze the effects of these data choices, we first reproduce the most cited factors in the literature with each original paper’s own data choices. We find that all factor risk premia have a point estimate with the same sign, but only one of the risk premia remains significant (i.e., only one positive reproduction). Then, to study robustness, we compute the return of each factor with the data choices from the other papers. Done this way, none of the factor risk premia are significant with the choices used in the other papers, a form of failure of scientific replication. In fact, the point estimate of the average excess return even changes sign in some cases.
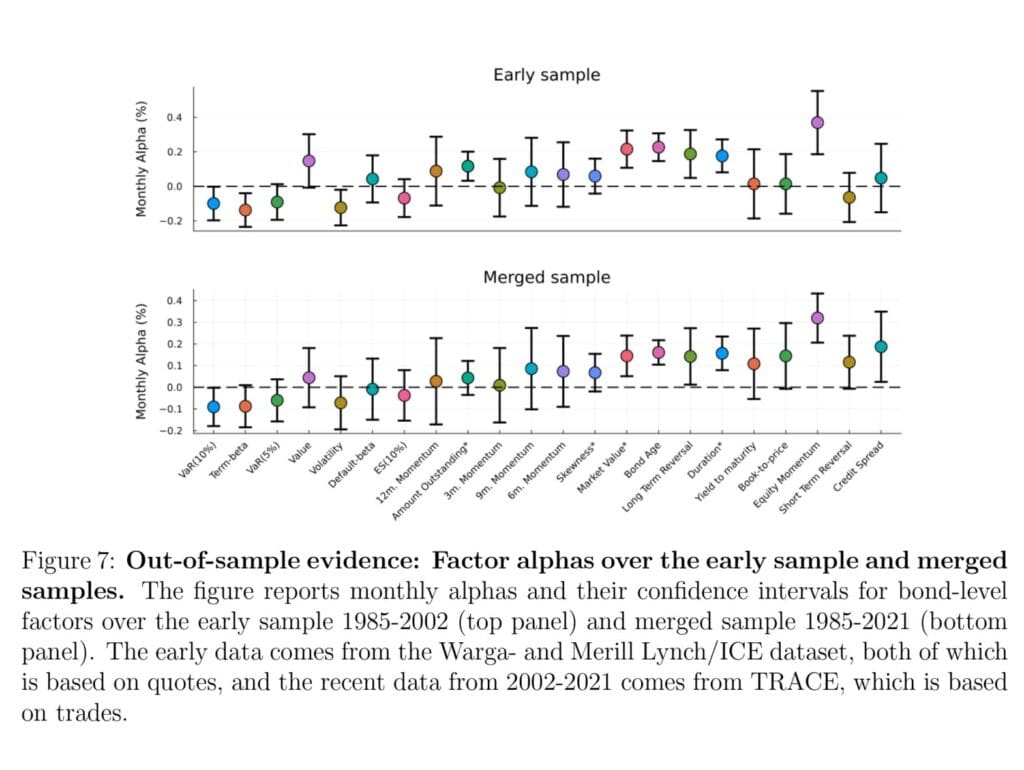
Clean data matters. We are not just interested in examining the credibility of the literature, we are also searching for the truth about credit market returns. Therefore, we seek to create a relatively clean data set of corporate bond returns. Rather than making arbitrary choices, we first apply filters that eliminate a range of known errors, and then analyze all the most extreme remaining outliers “by hand,” eliminating errors and retaining extreme returns that represent real economic events. Furthermore, we include returns around defaults. Using this clean data, we find that most corporate bond factors fail to replicate, even with each paper’s own factor construction methodology. At a more basic level, we find that the average return of the overall corporate bond market is meaningfully different using the clean data versus some of the data cleaning methods in the literature.
Scientific replication: A robust framework. While the literature uses different data-cleaning and factor-construction methods, we are interested in examining factor returns using the same clean data set and a consistent robust factor-construction method. In particular, the different papers in the literature use factor-construction methods based on (i) equal- or value-weighting; (ii) tertile, quintile, or decile portfolios; and (iii) single- or double-sorting. We argue that a robust method is to (i) value-weighted returns for implementability and to reduce the importance of missing returns; (ii) use tertile portfolios to include a large fraction of the data; and (iii) double-sort based on each signal and three broad credit-rating groups to ensure apples-to-apples comparisons.
Based on our clean data and robust factor construction method, we replicate all of the factors from the literature, and compute their alphas controlling for the overall credit market return and the overall Treasury bond return. We find that only 23% of the factors considered significant in the literature have significant alphas using our framework, as seen in the first bar in Figure 1. This finding reveals a surprisingly low scientific replication rate.
In summary, Figure 3 shows that portfolio construction matters even with common data, just like Figure 2 shows that data matters even with common portfolio construction. We focus from now on our common data and common methodology.
Figure 4 reports our scientific replication of all the corporate bond factors. The top panel shows each factor’s excess return and its confidence interval. Similarly, the bottom panel shows each factor’s alpha and its confidence interval, where the alpha is the intercept from the following regression of monthly factor excess returns on our corporate bond market factor, CMKT, and the TERM factor.”
Are you looking for more strategies to read about? Sign up for our newsletter or visit our Blog or Screener.
Do you want to learn more about Quantpedia Premium service? Check how Quantpedia works, our mission and Premium pricing offer.
Do you want to learn more about Quantpedia Pro service? Check its description, watch videos, review reporting capabilities and visit our pricing offer.
Are you looking for historical data or backtesting platforms? Check our list of Algo Trading Discounts.
Would you like free access to our services? Then, open an account with Lightspeed and enjoy one year of Quantpedia Premium at no cost.
Or follow us on:
Facebook Group, Facebook Page, Twitter, Linkedin, Medium or Youtube
Share onLinkedInTwitterFacebookRefer to a friend


















