Every market and financial asset has days where minutes might decide mid- and longer price trends and validate or reject investment ideas and theses in a few seconds. Forex (foreign exchange, currencies) traders prepare and long for NFP Fridays. If there were a Superbowl of Finance for equities, it’d definitely be FOMC (Federal Open Market Committee) meetings. Investors and traders from around the world gather and make their decisions on the brink of releasing a statement and following the press conference of the Chair, where they are often grilled with questions from curious journalists. Often, liquidity dries down, and volatility increases significantly during these events. People often digest and contemplate the Fed’s next moves and position themselves appropriately, making significant swings during that one trading afternoon. On top of that, add algo(rithm)s specifically programmed to act on release (AI parsing text and performing word sentiment analysis) and each vocal (text-to-speech) cue. Sometimes, it is better to take a breather, flatten positions, and wait for a complete release of all transcripts and documents, summarised in FOMC Minutes (example link). But sometimes, as this year’s edition of speeches at the Jackson Hole symposium, they can be taken as nothing-burger. An analysis of these and other related mentioned materials using LLMs (large language models) and ChatGPT is the topic of our recommended research paper.
Shah, Paturi, and Chava (May 2023) contribute with a new cleaned, tokenized, and labeled open-source dataset for FOMC text analysis of various data categories (meeting minutes, speeches, and press conferences). They also propose a new sequence classification task to classify sentences into different monetary policy stances (hawkish, dovish, and neutral) and show the application of this task by generating a hawkish-dovish classificationmeasure from the trained model.
They furthermore validate the measure by studying its relation with CPI, PPI, and Treasury yield. On top of that, they also propose a simple trading strategy that outperforms the high benchmark set by the QQQ index over the last decade.
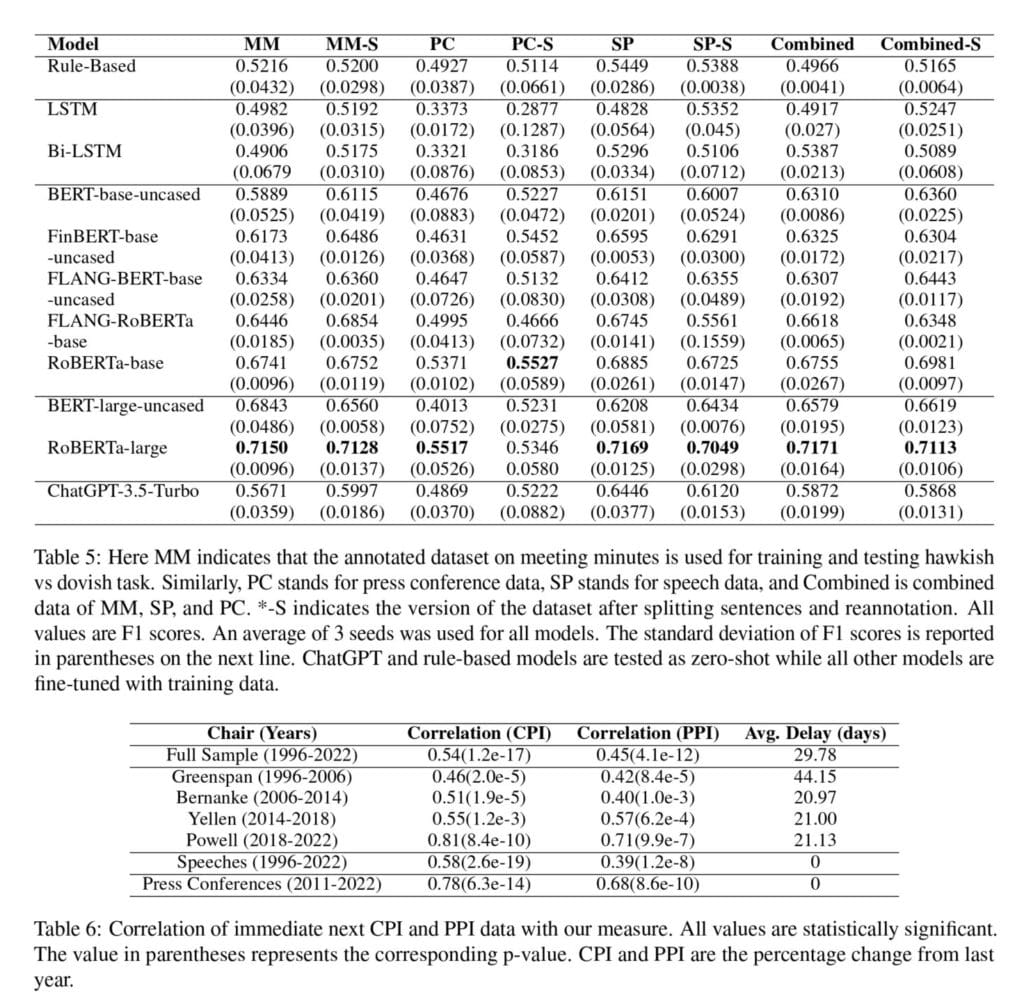
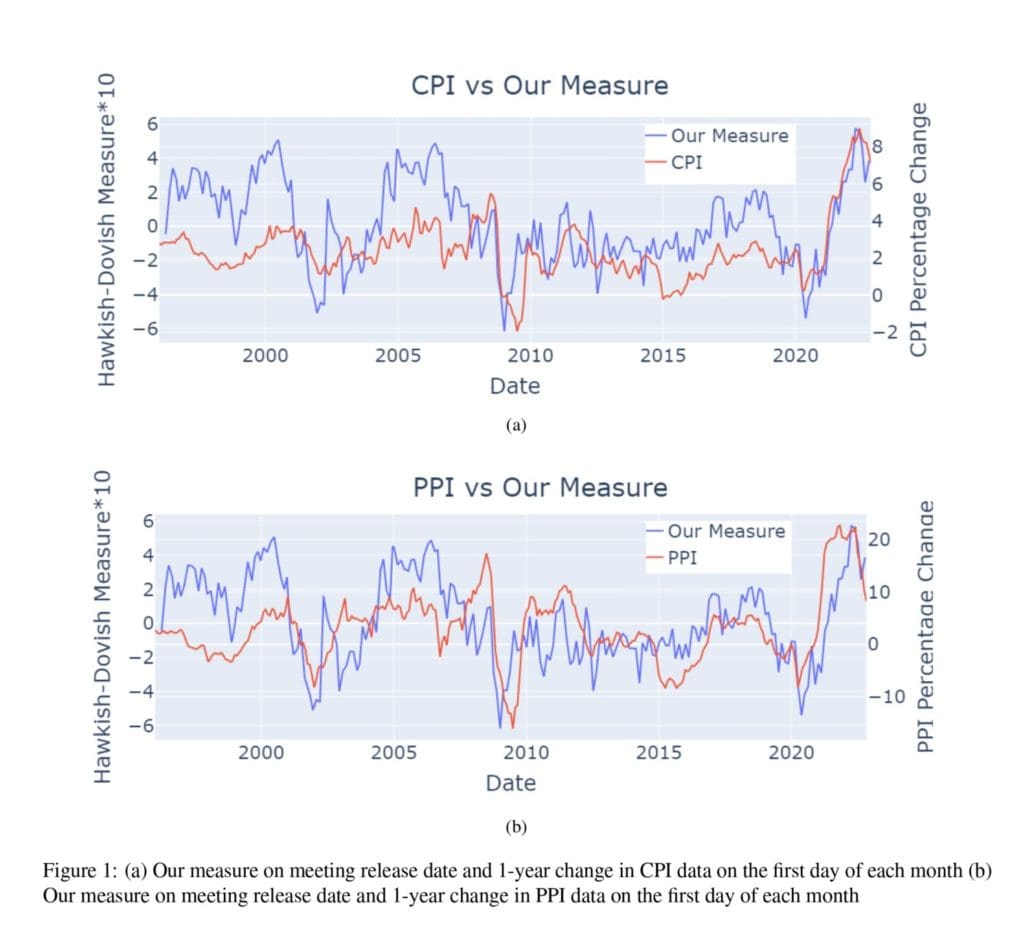
The results for the best hyper-parameters are listed in Table 5. The correlation of their hawkish-dovish measure with the CPI and PPI percentage change is in a Figure 1. As reported in Table 6, they found a statistically significant positive correlation for all three data classes. Table 10: Annotation Guide shows interesting classification authors have underdone.
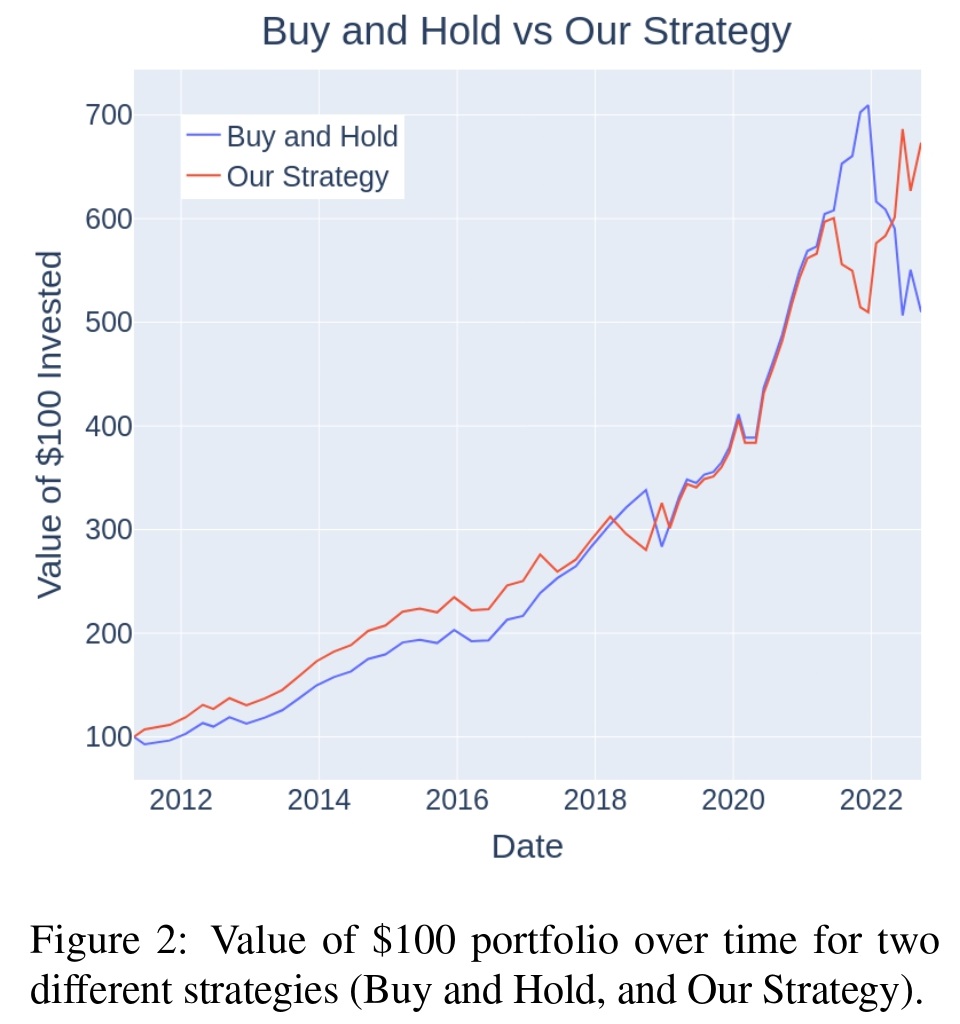
Authors also propose a trading strategy in which, one takes a short position of the QQQ [U.S. tech ETF, especially known for its sensitivity to interest rate changes] index fund when the hawkish-dovish measure is positive (hawkish) and a long QQQ position when the measure is negative (dovish). As shown in Figure 2, the presented strategy provides an excess return of 163.4% (673.29% the strategy vs. 509.89% buy and hold) compared to the buy and hold strategy as of September 21st, 2022 (since 2011).
Their models, code, and benchmark data can be found on Hugging Face and GitHub. Note that the trained model for monetary policy stance classification can be used on other FOMC-related texts, which is great as well.
Monetary policy pronouncements by Federal Open Market Committee (FOMC) are a major driver of financial market returns. We construct the largest tokenized and annotated dataset of FOMC speeches, meeting minutes, and press conference transcripts in order to understand how monetary policy influences financial markets. In this study, we develop a novel task of hawkish-dovish classification and benchmark various pre-trained language models on the proposed dataset. Using the best-performing model (RoBERTa-large), we construct a measure of monetary policy stance for the FOMC document release days. To evaluate the constructed measure, we study its impact on the treasury market, stock market, and macroeconomic indicators.
As always, we present several interesting figures and tables:
Notable quotations from the academic research paper:
“The Federal Open Market Committee (FOMC) is a federal organization responsible for controlling U.S.’s open market operations and setting interest rates. It tries to achieve its two main objectives of price stability and maximum employment by controlling the money supply in the market. Given the market condition (employment rate and inflation), the Fed either increases (dovish), decreases (hawkish), or maintains the money supply2 (neutral). To understand the influence the FOMC has on the different financial markets, we need to extract its monetary policy stance and the corresponding magnitude from official communications.
The datasets we build are composed of three different types of data: meeting minutes, press conference transcripts, and speeches from the FOMC. Meeting minutes are defined as reports derived from the eight annually scheduled meetings of the FOMC. Press conference transcripts, meanwhile, are transcripts of the prepared remarks, followed by the Q&A session between the Federal Reserve chair and press reporters. Lastly, speeches were defined as any talk given by a Federal Reserve official. We limit our datasets to an end release date of October 15th, 2022, and attempt to collect as far back as possible for each category prior to this Date.
Our dictionary filter was also applied to speech data. Speech data was the largest dataset derived from web scraping, however, speeches contained the most noise, owing to many non-monetary policy speeches. Unlike the meeting minutes and press conference transcripts, speech data was accompanied with a title, so to isolate only relevant FOMC speeches to sample from, we applied the dictionary filter discussed in Table 1 onto the title of each speech. We justify this procedure in Table 2 as this methodology results in the greatest “target” sentence per file. Overall, the filtration process isolated relevant files and “target” sentences in our raw data and set the stage for later sampling. The filter’s impact on the raw data is presented in Panel B of Table 3.
Sampling and Manual Annotation As our data was unlabeled, our analysis necessitated the usage of manual labeling. To efficiently develop a manually labeled dataset, sampling was required. Our sampling procedure was to extract 5 random sentences and compile a larger data set. If fewer than 5 sentences were present in the file, all sentences were added. This sampling procedure resulted in a 1,070-sentence Meeting Minutes dataset, a 315-sentence Press Conference dataset, and a 994- sentence Speech dataset. For the labeling process, sentences were categorized into three classes (0: Dovish, 1: Hawkish, and 2: Neutral). We annotate each category of the data as a model trained on various categories as a model trained on the same category of data does not perform optimally. We provide evidence for this claim in Appendix B. Dovish sentences were any sentence that indicates future monetary policy easing. Hawkish sentences were any sentence that would indicate a future monetary policy tightening. Meanwhile, neutral sentences were those with mixed sentiment, indicating no change in the monetary policy, or those that were not directly related to monetary policy stance.
[They] ran all models listed in the [Models] section on three different categories and combined data. For each dataset, we train and test each model on both the before-split and after-split versions of sentences. For each model, we use three different seeds (5768, 78516, 944601) and calculate the average weighted F1 scores. […] As expected the rule-based model doesn’t perform very well. The rule-based approach optimizes the time needed for classification, but sacrifices the nuance of complex sentences, which necessitate context. […] Although the LSTM and Bi-LSTM models are able to utilize greater context for classification, they did not perform significantly better than the initial rule-based approach. As seen across all data categories, the RNN models performed marginally the same. The LSTM and Bi-LSTM performances largely differed between the data categories. They performed worst when applied to the press conference datasets, a discrepancy caused by the small size of the dataset. […] finetuned PLMs outperform rule-based model and LSTM models by a significant margin. In base size, RoBERTa-base outperforms all other models on all datasets except after-split meeting minutes data (MM-S). On PC, FLANG- RoBERTa performs best. A future study using ablation states of models to understand why the finance domain-specific language models don’t outperform RoBERTa and how they can be improved could be fruitful. In large category and overall, RoBERTa large provide the best performance across all categories except PC-S. […] Zero-shot ChatGPT outperforms both rule-based and fine-tuned RNN-based (LSTM & Bi-LSTM) models.”
Quantpedia is The Encyclopedia of Quantitative Trading Strategies
We’ve already analysed tens of thousands of financial research papers and identified more than 700 attractive trading systems together with hundreds of related academic papers.
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Strictly Necessary Cookies
Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings.
If you disable this cookie, we will not be able to save your preferences. This means that every time you visit this website you will need to enable or disable cookies again.