The CAPE Ratio and Machine Learning
Professor Robert Shiller’s work and his famous CAPE (cyclically-adjusted price-to-earnings) ratio is well known among the investment community. His methodology for assessing a valuation of the U.S. equity market is not the first one but is surely the most cited and the most discussed. There are numerous papers that tweak or adjust Shiller’s methodology to assess better if U.S. equities are under- or over-valued. We recommend the work of Wang, Ahluwalia, Aliaga-Diaz, and Davis (all from The Vanguard Group ) in which they use a combination of machine learning and a regression-based approach to obtain forecasted CAPE ratio, and subsequently, U.S. stock market returns, more accurately.
Authors: Wang, Ahluwalia, Aliaga-Diaz, Davis
Title: The Best of Both Worlds: Forecasting US Equity Market Returns using a Hybrid Machine Learning – Time Series Approach
Link: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3497170
Abstract:
Predicting long-term equity market returns is of great importance for investors to strategically allocate their assets. We apply machine learning methods to forecast 10-year-ahead U.S. stock returns and compare the results to traditional Shiller regression-based forecasts more commonly used in the asset-management industry. Machine-learning forecasts have similar forecast errors to a traditional return forecast model based on lagged CAPE ratios. However, machine-learning forecasts have higher forecast errors than the regression-based, two-step approach of Davis et al [2018] that forecasts the CAPE ratio based on macroeconomic variables and then imputes stock returns. When we combine our two-step approach with machine learning to forecast CAPE ratios (a hybrid ML-VAR approach), U.S. stock return forecasts are statistically and economically more accurate than all other approaches. We discuss why and conclude with some best practices for both data scientists and economists in making real-world investment return forecasts.
Notable quotations from the academic research paper:
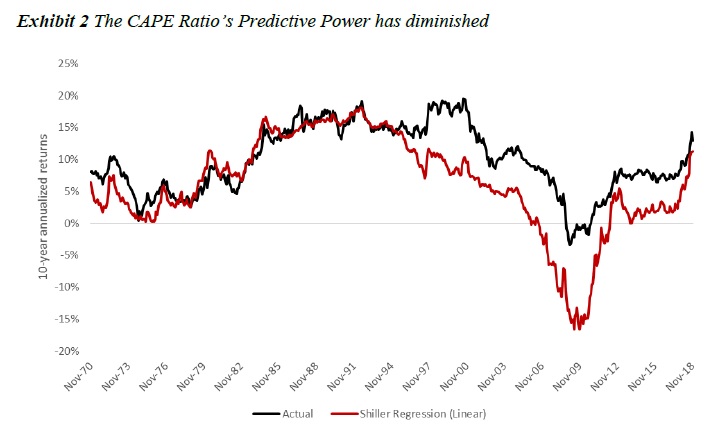
” A high CAPE ratio has been associated with below average 10-year-ahead U.S. stock returns and vice-versa. Typically, researchers express this relationship in terms of a linear regression (Shiller’s regression) of 10-year-ahead equity returns on the beginning period’s CAPE ratio. However, the accuracy of the Shiller regression has deteriorated since the 2000s.
| Algo Trading Promo Codes are available exclusively for Quantpedia’s readers. |
We extend the Shiller univariate regression to a multivariate regression, including CAPE, real interest rates, inflation, measures of financial volatility, stock variance, Treasury bill rates, the default yield spread, and the default return spread. We use 10-year ahead return as the predicted variable (Equation 2). Put simply, we attempt to forecast returns directly, just like the Shiller regression, but add a few important economic and market variables to the regression.

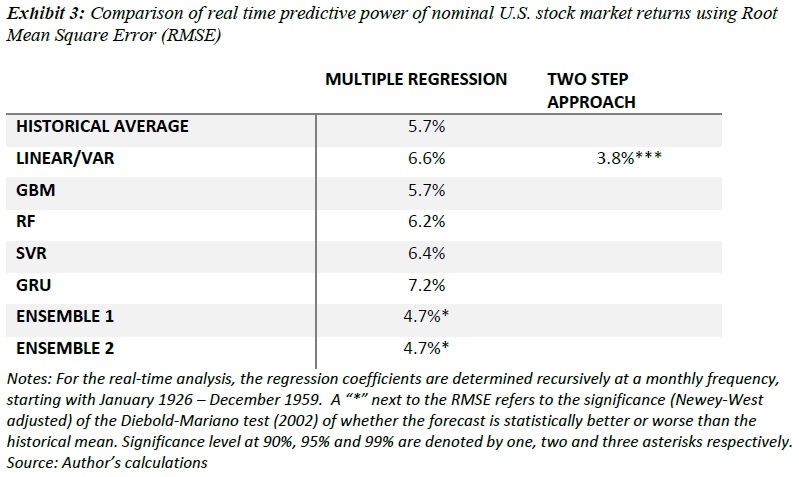
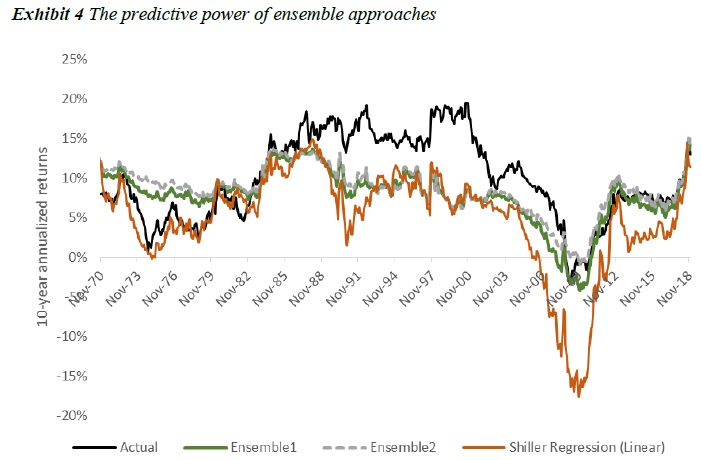
Exhibit 3 shows that the out-of-sample RMSE of the multiple regression comes out to be 6.6% while that of a naïve historical average forecast is 5.7%. Thus adding other important variables to a regression alone does not improve the forecasts. We directly forecast returns using ML algorithms, based on the same predictors. Exhibit 3 shows that none of the individual models are statistically better than the naïve historical average forecast. Put another way, real-time investors would have been better served using the historical average return as the baseline for future stock returns. Strikingly, only some ML methods demonstrated a small edge in predictive power over the linear regression. GRU performed particularly poorly in terms of RMSE. Despite the poor predictive power of individual models, we find an equally weighted combination of the all the ML model forecasts (Ensemble 1) and a combination of all the ML models and the traditional multiple regression (Ensemble 2) show a modest statistical improvement over the naïve forecast.
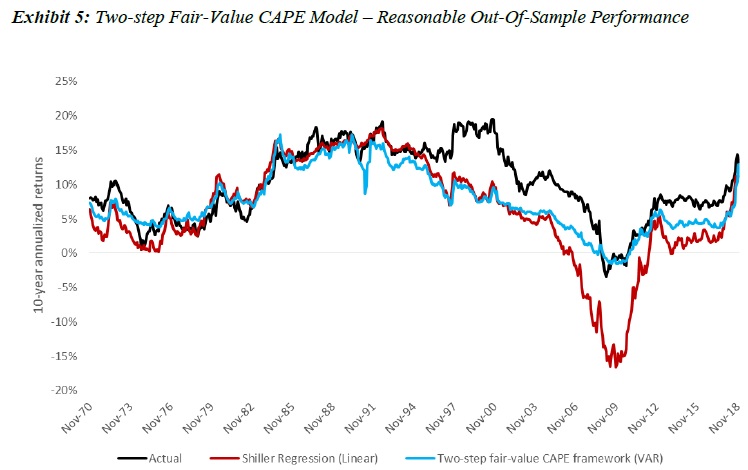
To address some of the potential issues regarding Shiller Regression discussed in the previous sections, Davis et al [2018] propose a two-step framework to forecast long-run equity market returns. The two-step approach is based on a VAR model to forecast the inverse of the CAPE ratio itself as the first step and to impute returns from the CAPE ratio in the second. More specifically, step one estimates a VAR model with 12 monthly lags of 1/CAPE, real 10-year bond yields, CPI inflation rate, realized S&P500 price volatility, and realized volatility of changes in real bond yield. In the second step, stock returns are imputed as a sum of three parts: valuation expansion; earnings growth; and dividend yield. At any one point in time, the VAR forecasts the CAPE earnings yields out for 10 years, and step two derives the expected future 10-year-ahead return on U.S. stocks.
.
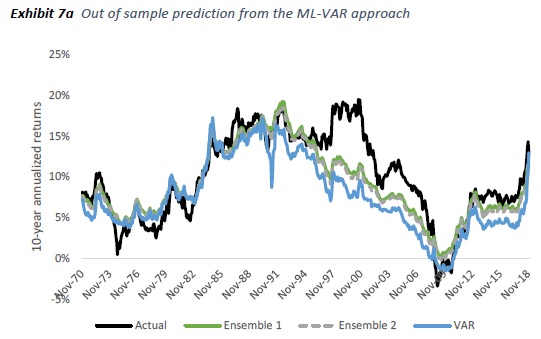
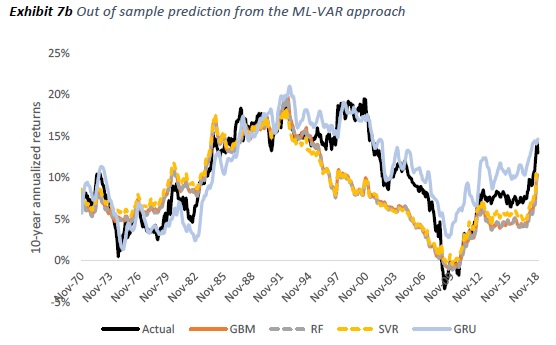
Building on the two-step framework above, we propose a refined framework that integrates ML methods with VAR to forecast the inverse of CAPE ratio. Importantly, we replace the linear core within the VAR with ML and forecast 1/CAPE, inflation, real yields, equity volatility, and bond volatility dynamically in a vector. We then use the same sum-of-parts identity used in Davis et al [2018]. The result is shown in Exhibit 6. The right column shows that all ML-VAR methods demonstrate remarkable improvement and have statistically lower average errors than the naïve historical average forecast. The ML-VAR methods also have lower forecast errors than the original two-step approach. We see the highest improvement (RMSE drops the most) in GRU where the RMSE improves to 2.6%. The RMSE of Ensemble 1 (2.6%) is marginally lower than GRU and that of Ensemble 2 (2.8%) closely trail GRU. More important, applying the robust two-step framework with ML algorithms drastically improves the forecast accuracy of all non-linear ML techniques relative to the forecasts from those same ML techniques used without the two step framework

Are you looking for more strategies to read about? Sign up for our newsletter or visit our Blog or Screener.
Do you want to learn more about Quantpedia Premium service? Check how Quantpedia works, our mission and Premium pricing offer.
Do you want to learn more about Quantpedia Pro service? Check its description, watch videos, review reporting capabilities and visit our pricing offer.
Do you want algorithmic access to the full Quantpedia database via the API? Subscribe to Quantpedia Pro, ask for an API key, and explore the in/out-of-sample statistics, source academic papers, and code snippets — ideal for quantitative research, systematic trading workflows, and AI model training.
Are you looking for historical data or backtesting platforms? Check our list of Algo Trading Discounts.
Or follow us on:
Facebook Group, Facebook Page, Telegram, Twitter, Linkedin, Medium or Youtube
Share onLinkedInTwitterFacebookRefer to a friend










