Metcalfe’s Law in Bitcoin
12.August 2019
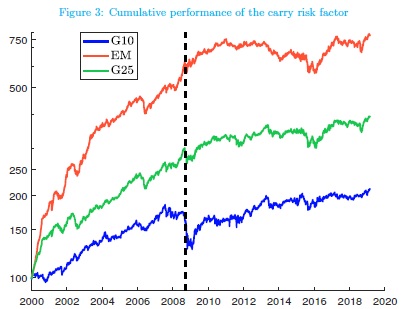
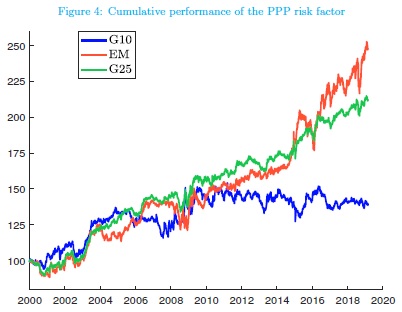
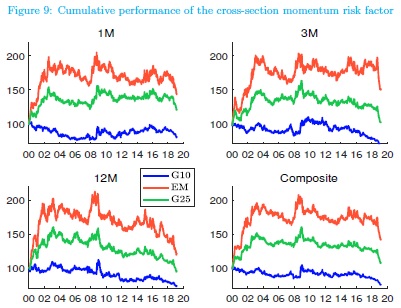
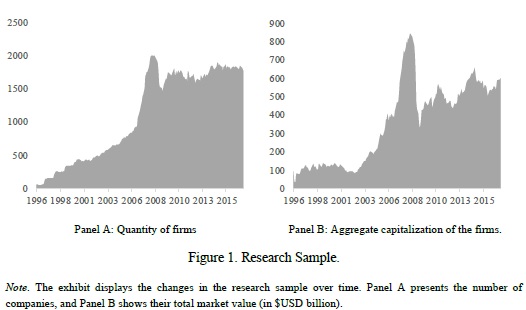
Cryptocurrencies are a new asset class, and researchers have just started to understand better fundamental forces which are behind their price action. A new research paper shows that Bitcoin’s price can be modeled by Metcalfe’s Law. Bitcoin (and other cryptocurrencies) are in this characteristic very similar to Facebook as their value depends on the number of active users – network size
Authors: Peterson
Title: Bitcoin Spreads Like a Virus